Microservices is a hot topic these days. The traditional way to design an application, also called monolithic, is facing several issues when the software becomes more significant. Microservices tend to overcome them by using a container-based approach.
What is a microservice?
Traditionally, we bundle the REST API, the business logic, and the data access layer into the same deployment unit. In this way, it is easy to deploy and test it. Unfortunately, this approach has some drawbacks when the application becomes more consequent like the difficulty of implementing new features, the limited agility, and the poor reliability. For these reasons, microservices architecture were introduced and are now gaining momentum. The software is divided into several independent services that communicate with each other to enable the horizontal scaling. It also prevent the application to completely crash when an exception occurs. In this project at iCoSys, we use microservices to bring deep learning models into production. These models generally perform only one specific task and can be chained to build a processing pipeline. Our experience is that microservices are very suitable for applications involving machine learning components thanks to the modular aspect and capacity to re-train and make evolve easily the models. In terms of technology stack, we have opted for Docker, Kubernetes and the use of OpenAPI, as explained in further details below.
Showcase
At iCoSys, we have set up a significant cluster of servers to deploy our microservices. It is currently used in the context of different research projects (innosuisse, EU, …) as test-bed for pre-deployment settings. It is also used for student projects and as demonstrator. Several machine learning services are currently showcased on our cluster and can me accessed from our showcase page:
- NLP – Language Identification. The language id is detected from one or several phrases given as input. Up to 10 languages are supported, as well as dialects (currently Swiss German).
- NLP – Word Embedding. This API allows to use 3 different word embedding methods (Word2Vec, FastText and GloVe) in 2 different languages. French and English languages are currently supported.
- Image – Object Detection. Up to 80 classes of objects are detected such as person, car, bicycle, bus, etc. Bounding boxes around the detected objects are also given as output.
- Image – Pose Detection. This microservice is able to identify the body, face and hands landmarks.
- Image – MeteoCam. This microservice allows to detect the road weather conditions from an image. Three road conditions are recognized: dry, wet/rainy and snow.
- Speech – Text-To-Speech. This microservice synthesizes audio that is understandable to humans from plain text. Currently, only English is supported.
- Tools – wExtract. This is a simple WebService for extracting text/images from web pages.
- …
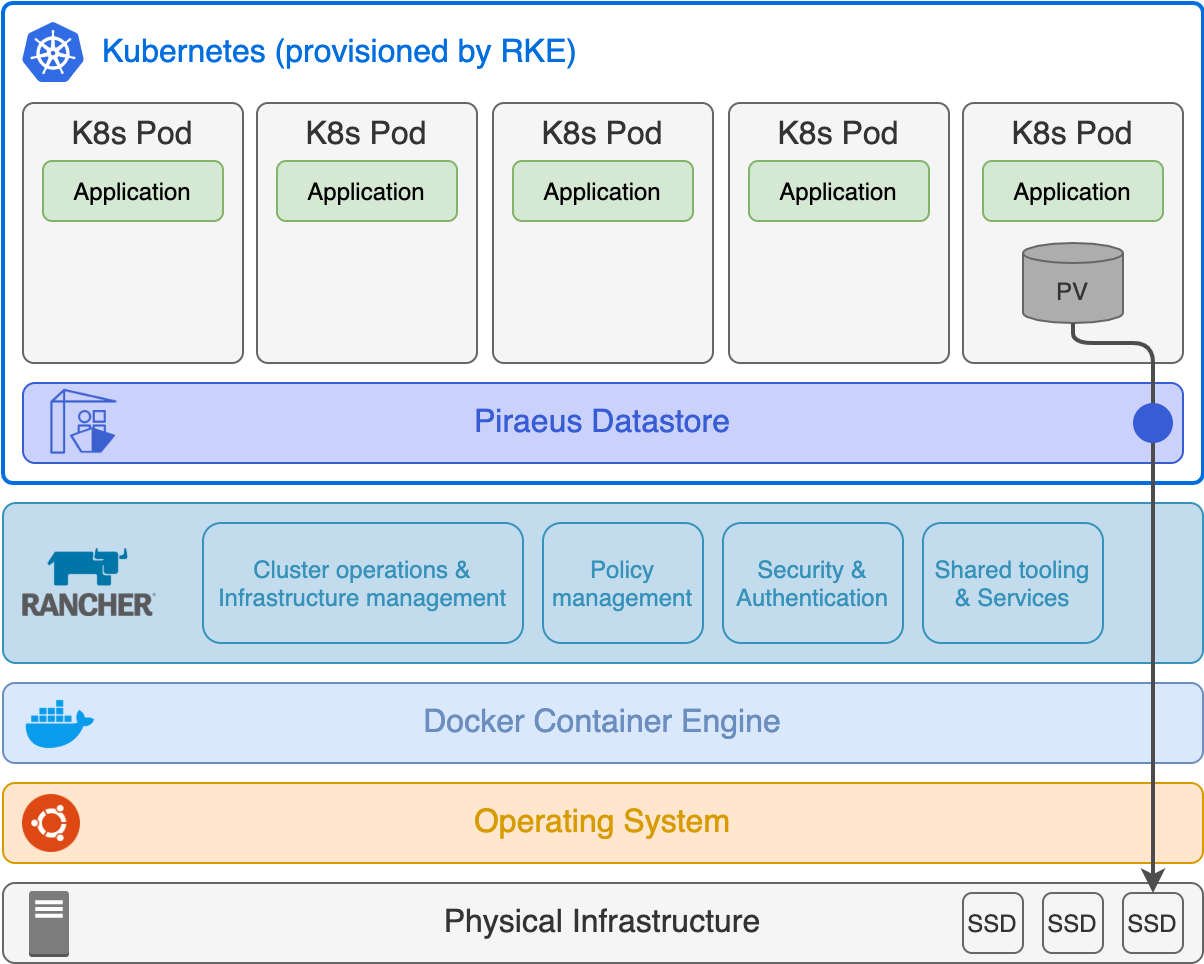
Kubernetes
Microservices are encapsulated into Docker containers to ensure isolation and portability. To deploy them into production, we use Kubernetes, a well-known container orchestrator. Kubernetes is an open-source project initially developed by Google and maintained by the Cloud Native Computing Foundation. It provides a way to automate the deployment, scaling, scheduling, and operation of multiple containers. At iCoSys, we have chosen Rancher as the Kubernetes Management Platform and Piraeus Datastore for persistent volumes provisioning. Here is a diagram of our technologic stack:
OpenAPI Specification
We have opted to make our microservices communicate by a REST API. To create documentation of each route, we use the OpenAPI Specification. It provides a standard interface description that is readable for both humans and machines to discover and understand the capabilities of each service easily.
? GPU support
We recently added GPU support to our microservices at iCoSys. This was needed to deploy some larger deep learning models as the Text-to-Speech one. By default, Kubernetes schedules only one container per GPU, which results in a considerable waste of computing resources since a container usually does not use the full power of a GPU. To avoid that, we use a GPU sharing scheduler to share a GPU between multiple containers. Contact us at info@icosys.ch if you are interested to get more information.