
BENEFRI 2025 Summer School
The BENEFRI summerschool, 2025 edition, is organised by the School of Engineering and Architecture of Fribourg (HEIA-FR – Sébastien Rumley). The BENEFRI gathers PhD students, senior researchers and professors active in the field of distributed systems, dependable systems and artificial intelligence from the schools and universities of BErn, NEuchatel and FRIbourg.
Participants
The 2025 edition is rich of 26 presentations, and will gather 40 people.
Students Bern (12): Marcio Moraeslopes, Hexu Xing, Fabrice Marggi, Elham Hasheminezhad, Sajedeh Norouzi, Jinxuan Chen, Sabyasachi Banik, Ivonne Nunez, Zimu Xu, Mingjing Sun, Solomon Wassie, Chuyang Gao
Students Neuchâtel (11): Mpoki Mwaisela, Romain Delaage, Julius Wenzel (also TU-Dresden), Sepideh Shamsizadeh, Abele Malan, Basile Lewandowski, Gert Lek, Abdessalam Ouaazki, Simon Queyrut, Pasquale Derosa, Louis Vialar
Students Fribourg (3): Dinhdung Van (also Uni Basel), Loïc Guibert, Michael Jungo
Seniors Bern (2): Torsten Braun, Eric Samikwa
Seniors Neuchâtel (6): Pascal Felber, Adrian Holzer, Vladimir Macko, Marcelo Pasin, Valerio Schiavoni, Peter Kropf, Peterson Yuhala
Seniors Fribourg (5): Sébastien Rumley, Jean Hennebert, Andreas Fischer (also UNI Fribourg), Beat Wolf, Berat Denizdurduran
Senior guests (1): Josef Spillner (ZHAW)
Where?
The 2025 edition will take place in Prangins, Vaud. Presentations will be hold in at the Prangins castle. The Prangins castle also host the French speaking site of the Swiss National Museum, see https://www.chateaudeprangins.ch/en for more information.
Hotel
Rooms for registered participants have been booked the hotel “La Barcarolle”. For the location of the hotel vis-a-vis of the castle, please see below.
How to get there?
Prangins castle is very easily accessible by public transport. Below the recommended schedule from Bern and Neuchâtel to get to the castle directly. If you want to come by car, please arrange parking with the hotel, or use a public parking located near the castle. Note, however, that you have to move your car every 2h or so.
 |
 |
General Program
Speakers are responsible for testing the HDMI connection as early as possible. Speakers are also asked to spontaneously announce themselves to the session chair (typically by staying in the room during the break preceding the session). Session chairs may require speakers to use a single laptop.
Owing to the large number of presentations, slots have been reduced to 25min. Authors are recommended to present for 15min and keep 10min for Q&A and speaker switching, unless instructed otherwise by session chairs.
Wednesday August 27th |
|
| 13h15 – 13h45 | Coffee and Welcome |
| 13h45 – 15h00 | Session 1 – Privacy-Preserving AI and Secure Computation – Chair : Marcelo Pasin
|
| 15h00 – 15h25 | Break |
| 15h25 – 16h40 | Session 2 – Distributed Architectures and Systems – Chair :
|
| 16h40 – 16h45 | Break |
| 16h45 – 18h00 | Session 3 – Federated & Transfer Learning (1) – Chair : Eric Samikwa
|
| 18h15 – 18h30 | Move to hotel “La Barcarolle” |
| 18h30 – 19h00 | Check-in and settling |
| 19h30 – 21h30 | Dinner (included) – Restaurant “Les Abériaux” |
Thursday August 28th |
|
| 7h30 – 8h15 | Breakfast |
| 8h15 – 8h30 | Move to Prangins castle |
| 8h30 – 10h10 | Session 4 – Generative AI: Risks and Applications – Chair :
|
| 10h10 – 10h30 | Break |
| 10h30 – 12h10 | Session 5 – Energy, Energy efficiency and sustainability – Chair : Sébastien Rumley
|
| 12h10 – 13h00 | Move to hotel, prepare bags etc. |
| 13h – 21h30 | Social hike (incl. picnic) + event incl. Dinner |
Friday August 29th |
|
| 7h30 – 8h15 | Breakfast |
| 8h15 – 8h30 | Move to castle |
| 8h30 – 9h45 | Session 6 – Immersive AI and Mixed Reality – Chair : Beat Wolf
|
| 9h45 – 10h00 | Break |
| 10h00 – 11h15 | Session 7 – Reinforcement Learning and Optimization – Chair : Berat Denizdurduran
|
| 11h15 – 11h30 | Break |
| 11h30 – 12h45 | Session 8 – Applied Security for AI & Systems – Chair : Valerio Schiavoni
|
Social activities and meals
Please note that lunch of Wednesday is not included. There are several restaurants in Prangins, one of them located in the castle, would participant want to eat there just before the beginning of the event.
On Wednesday night, tables have been reserved at the restaurant “Les Abériaux”, which conveniently located 200m away from the hôtel, and 300m away from the castle (see plan below). Wednesday dinner is included.
Thursday afternoon has been kept free for the traditional hike (weather permitting). We will first go to Prangins beach. Participants are advised to take swimsuits and towels with them to enjoy a swim in Léman lake. We will then walk 10km, and 250m ascent to a surprise place where we should arrive around 5.30p. Please take with you:
- Swimsuit and towel
- Shoes you are confortable to walk with, also on gravel)
- Water bottle to drink during the hike, to be filled along the way
- Jacket in case of light rain
A picnic (incl. – no beverage) will be organised. Details will be fixed on Wednesday.
After the surprise, we will move to a nearby restaurant (https://www.aubergedeluins.ch) to eat the famous “Malakoffs”. Malakoffs are cheese beignets. A bus has been reserved to bring everyone back to Prangins after the dinner.
Participants not wanting to take the “all-you-can-eat” Malakoff menu will be offered a vegetarian menu (two options).
Participants not wanting to walk the full hike can reach the restaurant by taking the 811 bus to Gland (see plan below), and then the 835 bus to Luins. There is one connection every hour.
Participants not wanting to attend the Thursday dinner altogether must contact the organiser BEFORE Tuesday 25th, as the restaurant has asked for the exact number of guests to be communicated. Participants failing to advise might be charged for.
Room allocations
Names of participants and allocations to rooms have already been communicated to the hotel. Please respect the allocation, at least at first.
Food restrictions
Vegetarian :
- Gert Lek
- Loïc Guibert
Plan
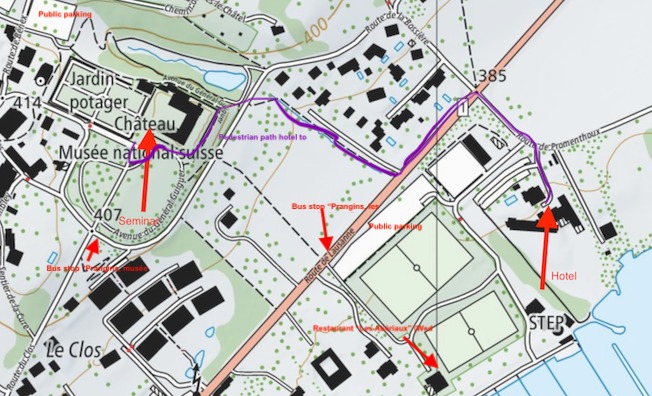
Presentation abstracts
|
Privacy-preserving processing has become an indispensable requirement in the contemporary computing landscape, particularly with the proliferation of cloud platforms that routinely manage and analyze massive volumes of data. Conventional privacy-preserving techniques, including secure multiparty computation, homomorphic encryption, and differential privacy, provide strong protection guarantees but impose considerable computational and communication overheads, thereby limiting their practicality at scale. A key source of inefficiency arises from the substantial cost of data movement between processing units and memory, which dominates overall execution time and energy consumption. Processing-in-memory (PIM) architectures mitigate this bottleneck by enabling computation directly within or near the memory substrate, thereby reducing data transfer overhead and improving throughput. The convergence of PIM with privacy-preserving paradigms presents a promising direction for scalable, high-performance, and secure data processing, offering the potential to reconcile the long-standing trade-off between privacy and efficiency in large-scale systems |
|
Fully homomorphic encryption (FHE) and trusted execution environments (TEE) are two approaches to provide confidentiality during data processing. Each approach has its own strengths and weaknesses. In certain scenarios, computations can be carried out in a hybrid environment, using both FHE and TEE. However, processing data in such hybrid settings presents challenges, as it requires to adapt and rewrite the algorithms for the chosen technique. We propose a system for secure computation that allows to express the computations to perform and execute them using a backend that leverages either FHE or TEE, depending on what is available. |
|
Even if AI decisions will always remain a black box, there is much room of improvement regarding reliable documentation. In sensitive areas (such as mushroom identification), users might ask for additional information regarding the origins and genesis of an AI decision. In an analogy to Software Bill of Materials (SBOMs), we suggest a “Decision Bill of materials”, a unified document detailing training and inference details. We use signatures to ensure accountability and provide options to run training processes in Confidential Computing. The latter allows us to run training and inference on potentially malicious environments. We also provide an example set-up where users can get detailed information about one particular AI training and inference |
|
Distributed Machine Learning (DML) increasingly relies on data and compute spread across heterogeneous, multi-domain environments. While the Cloud Continuum (CC) offers a vertical hierarchy (IoT–Edge–Fog–Cloud) and Cloud Federation (CF) enables horizontal, inter-domain collaboration, an effective integration of CC and CF remains an open challenge. This talk frames the key obstacles, system heterogeneity, policy- and governance-aware orchestration, and efficient cross-domain coordination, then reviews state-of-the-art hierarchical and federated learning approaches, highlighting why none alone delivers a unified solution. We conclude with a path forward: an integrated CC/CF architecture designed to improve scalability for large-scale DML, illustrated with a modular design and a case-driven evaluation plan. |
|
This talk presents a generalized framework for AI-oriented architectures in distributed systems that transform heterogeneous data into domain-specific insights. Across agriculture, cloud observability, and university management, the framework integrates streaming data with specialized models—ranging from large-scale learned models to compact, fact-driven ones—while addressing limited ground truth, multimodal fusion, and data/computational-scale trade-offs. The approach is illustrated briefly with AlpTracker (animal-movement modeling with adaptive fuzzy inference), NearbyOne (MCP-augmented LLM for edge–cloud orchestration), and an IC credential wallet (decentralized storage and sharing). The talk then deepens into the agricultural/IoT domain to show how these design choices enable reliable, large-scale, context-aware analysis and decision-making, and will include concrete metrics on data volume and compute requirements. |
|
Extended Reality (XR) applications, such as immersive city tours, demand efficient and low-latency content distribution to deliver seamless and realistic user experiences. Traditional network architectures, relying heavily on centralized servers, struggle to meet these stringent latency requirements due to limited bandwidth, significant communication delays, and frequent user mobility. To address these challenges, we propose a Floating Named Network (FNN), a decentralized, content-centric network architecture that integrates floating content strategies to support dynamic XR environments. Central to FNN are Group Owners (GOs), which act as local coordinators managing dynamic groups of user nodes, maintaining real-time awareness of localized content caches, while enabling latency-aware, multi-hop named-data routing. Our floating content mechanism ensures proactive replication and dynamic distribution of popular content within these groups, significantly reducing content retrieval delays. Furthermore, FNN employs an efficient routing exchange protocol among neighboring GOs, facilitating rapid adaptation to changes in network topology and content availability. We evaluate our architecture using a realistic XR-based city tour scenario, demonstrating a latency reduction opportunity of 23.5\% and a content retrieval latency improvement of 82%. These results indicate that the proposed floating content strategy effectively meets the demanding performance requirements of emerging XR applications.
|
|
Transportation systems are shaped by multiple transport modes and their interactions. Planning and management increasingly rely on understanding these interplays; accordingly, cross-modal predictions offer the potential to improve forecasts for individual modes of transport. However, data privacy concerns hinder data sharing across providers. This paper presents a Federated Learning framework for cross-modal transport flow and demand prediction, enabling multiple transport organizations to collaboratively enhance prediction accuracy while preserving data privacy, especially spatial information. Our approach integrates data across transport modes and addresses data heterogeneity and sparse sensor coverage. Evaluations on two real-world cross-modal datasets show that the proposed model improves prediction accuracy, especially for transport modes with fewer data. The framework adapts to varying transport network sizes and generalizes well across heterogeneous environments, demonstrating the practical value of privacy-preserving collaboration for building resilient and adaptive mobility systems. |
|
The orchestrators’ deployment problem presents numerous challenges in 6G Network Radio Access Networks due to their large-scale, dynamic conditions, and variable user demands. Most works propose single- or hierarchical-orchestrator solutions, which offer poor resiliency, high signaling overhead, and slow adaptation to variable network dynamics. To tackle these challenges, we propose an online, data-driven, fully decentralized, Multi-Agent Reinforcement Learning (MARL)-based, self-organization orchestrator deployment system for 6G networks, which jointly optimizes the tradeoff between user throughput and fairness, based on time-varying system conditions. In the proposed approach, a flexible variable number of decentralized, cooperative, peer self-organization agents autonomously adapt their associated orchestrator’s deployment location and activity to optimize network operation, without requiring centralized coordination. In the next part, we present a federated reinforcement learning approach to optimize controller placement policy with the aim of reducing communication overhead among Inter-domain and Intra-domain connections while increasing user throughput in the network. |
|
Effective channel estimation (CE) is critical for optimizing the performance of 5G New Radio (NR) systems, particularly in dynamic environments where traditional methods struggle with complexity and adaptability. This paper introduces GraphNet, a novel, lightweight Graph Neural Network (GNN)-based estimator designed to enhance CE in 5G NR. Our proposed method utilizes a GNN architecture that minimizes computational overhead while capturing essential features necessary for accurate CE. We evaluate GraphNet across various channel conditions, from slow-varying to highly dynamic environments, and compare its performance to ChannelNet, a well-known deep learning-based CE method. GraphNet not only matches ChannelNet’s performance in stable conditions but significantly outperforms it in high-variation scenarios, particularly in terms of Block Error Rate. It also includes built-in noise estimation that enhances robustness in challenging channel conditions. Furthermore, its significantly lighter computational footprint makes GraphNet highly suitable for real-time deployment, especially on edge devices with limited computational resources. By underscoring the potential of GNNs to transform CE processes, GraphNet offers a scalable and robust solution that aligns with the evolving demands of 5G technologies, highlighting its efficiency and performance as a next-generation solution for wireless communication systems. |
|
Deep neural networks using diffusion, and related approaches, are state-of-the-art for modelling complex distributions of graph data. We discuss two areas of concern identified in exploring the limitations of their generalization capabilities. A first limitation widely affecting such models is the quality breakdown when generating graphs with a size (i.e., number of nodes) outside the training data range. The issue is particularly potent when generating graphs with more nodes than seen during training. We investigate a method for stitching together multiple partly overlapping generated subgraphs to preserve important graph properties without retraining on a new dataset. Secondly, unlike other data modalities, limited analysis exists on the risks of generators revealing graphs from training data. Quantitatively estimating such risks is crucial when models train on privately identifiable data (e.g., a person’s social circle). As a proposed solution, we adapt an existing tabular data framework to incorporate graph connectivity patterns alongside any available node attributes. |
|
The fast development of artificial image generation has led to a surge in the amount of Text-to-Image (T2I) pre-trained models publicly available. While the state-of-the-art performance is heavily contested, no model has achieved overall supremacy: each remains the superior choice in a specific field. Therefore, we have designed algorithmic solutions to address this issue by training selection frameworks that enable users to determine the best-suited model for their needs beforehand. In this presentation, we will discuss the challenges arising from the current situation and detail our proposed designs to answer these problems under different constraints. |
|
Image forgery localization in the diffusion era poses new challenges as modern editing pipelines produce photorealistic, semantically coherent manipulations that bypass conventional detectors. We present this problem and (our) recent ways to tackle it. |
|
Computational thinking (CT) skills are essential to teach, and Generative AI (GenAI) could transform how these skills are learned. While educators are rapidly adopting GenAI, best practices remain unclear. Existing reviews are either too broad (focusing on tools like ChatGPT for general learning) or too narrow (focusing on CT mainly through programming). This paper summarizes current knowledge and identifies best practices and future research directions on GenAI and CT. Its contributions are: (1) insights from a systematic scoping review on GenAI use for teaching CT skills and reported outcomes, and (2) design guidelines for effective pedagogical use. Findings show a young but fast-growing field, with most studies targeting undergraduates and programming tasks using off-the-shelf tools. GenAI is used as coder, tutor, debugger, or ideator, with mixed learning outcomes. A major challenge is beginners’ overreliance versus advanced learners’ under-utilization. Seven guidelines are proposed to support effective, responsible GenAI integration in CT education. |
|
ICT represent a significant share of global resource usage. Notably, the energy consumption of data centres has emerged as a critical concern, escalating rapidly, especially with the rise of generative Artificial Intelligence (AI) models. This surge in energy demand calls for efforts focused on measuring and reducing the energy and carbon footprints of components used in ICT service delivery. However, the variety and multitude of devices involved in these services make it challenging to accurately measure and evaluate these footprints. To assess such impacts, we defined a simple experimental testbed and evaluated several machines with different hardware capacities. These machines serve two different ICT services, allowing us to obtain valuable data on their energy consumption. By combining those data with server fabrication using Life-Cycle Analysis (LCA) and operational energy contribution to data center carbon footprint, we defined a novel 2D representation allowing to partition server carbon footprints into fabrication (embodied carbon), static operational power, and dynamic operational power. Interesting takeaways and effective mitigation strategies to reduce overall impacts have been identified. |
|
Modern autonomous vehicles rely on multimodal perception, including GPS, LiDAR, and cameras, to deliver accurate environmental understanding, positioning, and redundancy that improves decision-making. Fully exploiting multi-sensors enhances multimodal beamforming, and federated learning preserves privacy by avoiding the transmission of sensitive raw data to a central server. However, existing FL-based approaches to multimodal beamforming often overlook system heterogeneity across vehicle systems, leading to excessive computation overhead and energy consumption. In this paper, we propose a lightweight federated split learning framework for efficient multimodal beamforming by collaborative distribution learning with MEC servers. Evaluations on real-world datasets demonstrate the robustness and efficiency of the proposed method compared with state-of-the-art baselines. |
|
Heterogeneous edge devices offer opportunities for distributed intelligence, but is accompanied by computational and communication constraints. Federated Transfer Learning (FTL) addresses these challenges by enabling privacy-preserving, faster, and communication-efficient training. We propose a resource aware federated transfer learning framework, combining capability-aware model scaling and Adaptive Channel Attention (CACA) to optimize training time, and communication under device constraints without sacrificing model performance. Across varied client configurations, our model achieves 2–6× lower communication cost and ≥9% faster training than state-of-the-art FTL which demonstrates the practical viability of energy-aware FL through proportional scaling and capability-aware optimization. |
|
Accurate prediction of residential energy demand has become a critical challenge in the face of increasing home electrification, the integration of distributed renewable sources, and the heterogeneity of consumption data. This complexity is exacerbated by privacy constraints, temporal variability, and the limited ability of traditional centralized models to adapt to dynamic environments, making it challenging to develop scalable, interpretable, and efficient solutions. In response to this scenario, this work presents a new privacy-preserving framework for multivariate energy forecasting in smart homes, combining deep temporal modeling, user segmentation, personalization, and explainable AI techniques. The approach adapts predictive models to the heterogeneous behaviors of households while ensuring interpretability and operational efficiency, demonstrating consistent improvements in accuracy, adaptability, and transparency compared to traditional centralized and standard federated learning methods. |
|
Mobile Mixed Reality Networks (MMRNs) are emerging decentralized, infrastructure-free systems that allow users to interact in a shared space blending real and virtual worlds through mobile Head-Mounted Devices (HMDs). These immersive experiences increasingly depend on Artificial Intelligence (AI) services such as viewport prediction, object recognition, and scene understanding to enable responsive and context-aware interactions. However, the limited computational and communication capabilities of HMDs make it difficult to support AI services locally. To address this challenge, we propose FAST (Floating AI Service with Adaptive Pruning and Proximity-Based Model Sharing), a fully decentralized framework for scalable and resource-efficient AI service provisioning in MMRNs. FAST leverages device-to-device (D2D) communication to facilitate proximity-based model sharing among nearby users while dynamically adjusting model complexity through resource-aware pruning. Under full-information feedback, where each HMD observes gradients of its prediction loss, we design an online saddle-point algorithm with theoretical guarantees of sublinear regret and constraint violation. We further extend FAST to a QoE-feedback setting, where each HMD only observes its local prediction loss at two random points, and establish comparable performance bounds. |
|
Ancient Greek handwriting on papyrus is often degraded, resulting in multiple plausible writing trajectories that challenge traditional handwriting trajectory recovery methods. This study integrates expert knowledge from motion data and letterform hypotheses to improve handwriting trajectory recovery in degraded and fragmented scripts. |
|
Federated Learning (FL) for monitoring psychological states through smartphone sensor data holds significant promise for enabling personalized mental health interventions while preserving user privacy. However, the inherent heterogeneity in individual behaviors and data distributions presents substantial challenges for developing generalized models. To address these challenges, we propose GLAD-FL (Global-Local Adaptive Decomposition for personalized Federated Learning), a framework that integrates hierarchical modeling with a theoretically grounded regularization approach. GLAD-FL decomposes the predictive modeling process into shared global patterns and individual-specific adaptations, enabling flexible personalization while benefiting from collaboratively learned global knowledge. A novel regularization term derived from Rademacher complexity bounds is introduced to rigorously balance personalization and generalization, thereby mitigating overfitting risks associated with data heterogeneity. This theoretically justified regularization guides the adaptive selection of each user’s personalization level and incorporates a built-in few-shot safeguard for data-scarce clients, enhancing both model interpretability and robustness. Extensive evaluations on a real-world psychological dataset and standard benchmark datasets demonstrate that GLAD-FL consistently outperforms existing methods, including local training, centralized approaches, and other personalized FL techniques. |
|
The Cloud Continuum Framework (CCF) extends computing capabilities across near-edge, far-edge, and extreme-edge nodes beyond the traditional edge to meet the diverse performance demands of emerging 6G applications. While Deep Reinforcement Learning (DRL) has demonstrated potential in automating Virtual Network Function (VNF) migration by learning optimal policies, centralized DRL-based orchestration faces challenges related to scalability and limited visibility in distributed, heterogeneous network environments. To address these limitations, we introduce MARC-6G (Multi-Agent Reinforcement Learning for Distributed Context-Aware Service Function Chain (SFC) Deployment and Migration in 6G Networks), a novel framework that leverages decentralized agents for distributed, dynamic, and service-aware SFC placement and migration. MARC-6G allows agents to monitor different portions of the network, collaboratively optimize network control policies via experience sharing, and make local decisions that collectively enhance global orchestration under time-varying traffic conditions. We show through simulations that our proposed method, MARC6G, improves deployment efficiency, reduces migration costs by 34%, and lowers energy consumption by 12.5% compared to the state-of-the-art centralized DRL baseline. |
|
Reinforcement Learning (RL) has become a staple in the training of Large Language Models (LLMs) and since DeepSeek-R1 demonstrated the success of simple verifiable rewards, RL has started to make its way to downstream tasks. Due to its reduced complexity, rule-based RL has become a viable option even for more traditional tasks such as classification. We studied the differences between rule-based RL and supervised fine-tuning applied to Vision Language Models (VLMs) in the context of Document Image Classification, in particular their generalisation capabilities to out-of-distribution data. |
|
We propose a series of acceleration algorithms based on the Moreau envelope and the Fast Iterative Shrinkage-Thresholding Algorithm (FISTA) for deep Q-network training and VR video caching. |
|
The ubiquity of Android devices and their security vulnerabilities necessitate robust tools for automatic code analysis and malware detection. In this paper, we estimate the capabilities of Large Language Models in deobfuscating Android apps protected with the popular identifier renaming technique. Being the first study for this technique, we develop annotated datasets of obfuscated Android apps that may be of independent interest. Using these datasets, we conduct experiments using CodeLLaMA, LLaMA-4 and GPT-4.1. We include in the comparison DeobfuscaThor, a specialized DL-based solution that we design around the specific traits of this obfuscation. An extensive evaluation shows that DeobfuscaThor achieves better accuracy than state-of-the-art LLMs. |
|
The Ethereum Virtual Machine (EVM) is a decentralized computing engine. It enables the Ethereum blockchain to execute smart contracts and decentralized applications (dApps). The increasing adoption of Ethereum sparked the rise of phishing activities. Phishing attacks often target users through deceptive means, e.g., fake websites, wallet scams, or malicious smart contracts, aiming to steal sensitive information or funds. A timely detection of phishing activities in the EVM is therefore crucial to preserve the user trust and network integrity. Some state-of-the art approaches to phishing detection in smart contracts rely on the online analysis of transactions and their traces. However, replaying transactions often exposes sensitive user data and interactions, with several security concerns. PhishingHook is a new framework that applies machine learning techniques to detect phishing activities in smart contracts by directly analyzing the contract’s bytecode and its constituent opcodes. We evaluate the efficacy of such techniques in identifying malicious patterns, suspicious function calls, or anomalous behaviors within the contract’s code itself before it is deployed or interacted with. We experimentally compare 16 techniques, belonging to four main categories (Histogram Similarity Classifiers, Vision Models, Language Models and Vulnerability Detection Models), using 7,000 real-world malware smart contracts. Our results demonstrate the efficiency of PhishingHook in performing phishing classification systems, with about 90% average accuracy among all the models.
|
|
Trusted Execution Environments, such as Intel SGX or AMD-SEV, are a hardware security feature of modern micro-processors which enable running processes or virtual machines fully isolated from their host system, providing confidentiality guarantees to the deployer of the program, even in the presence of a malicious host. In addition, TEEs usually come with a remote attestation feature, which allow a third party to remotely assess if a program is running in a correctly configured TEE.
While Intel SGX protected one process at a time, therefore reducing the amount of code one has to trust and making it easier to attest, it required special care when preparing programs. For this reason, the industry has moved to virtual-machine based TEEs, where the security processor isolates an entire virtual machine from its host. This has the benefit of making most programs easy to run in a TEE, but has the inconvenience of increasing the amount of trusted code (a full Linux machine vs a single process), and making it harder to reason about attestation (what about the VM can you verify to make sure that a given program is properly deployed and configured?).
To address these issues, we propose Secret-Hermit, a unikernel written in Rust that can target the AMD-SEV execution environment. Based on the Hermit unikernel, Secret-Hermit implements the required modifications in order to run on the AMD-SEV platform. Its unikernel architecture reduces the amount of trusted code, as only the user application and kernel are part of the bootable image. In addition, we provide a full chain of trust, going from EFI firmware (EFI) to the underlying application, making it easy to verify which kernel binary is running in a trusted VM.
|